Workstation Intel reciente con SGX habilitado, Windows 11, perfil de uso mixto: durante la jornada cargan enclaves para servicios de atestación remota, un runtime confidencial basado en el Intel SGX SDK, y un cliente de juegos que en sus ratos libres invoca un anticheat también basado en enclaves. Por encima de todo eso, la imagen corporativa ha instalado un agente de seguridad EDR con un módulo comercial. El usuario reporta:
BSOD intermitentes, dos o tres por semana, sin coincidir nunca con la misma aplicación en foco.
Bug check siempre el mismo: 0x133 (DPC_WATCHDOG_VIOLATION).
Una correlación que sólo aparece después de mirar mucho: los crashes son más probables durante sesiones largas con enclaves activos. No es determinista; es una distribución sesgada.
El primer reflejo es revisar drivers gráficos (y en mi experiencia cabe destacar un crash importante en un servidor de BB.DD. al actualizar los drivers gráficos, allá por el año 2000, asi que no es extraño sospechar), de red y de almacenamiento. El segundo (también malo) es pasar el verifier.exe en modo paranoico, lo que dispara más BSODs sin acercar la respuesta. El tercero (el útil) es preguntarse qué dice exactamente WER.
Abrimos CrashDetectorwithAI tras el siguiente crash. La aplicación presenta de forma estructurada algo equivalente a esto:
Y, debajo, la respuesta del modelo local (Phi-4 vía ONNX) en streaming, que viene a decir, con palabras propias y prudentes, algo como:
Se trata de un DPC_WATCHDOG_VIOLATION. El parámetro 1 con valor 0 indica que se ha superado el umbral acumulado de DPC en un solo procesador. Los valores 0x501 y 0x500 son los ticks observado y permitido, expresados en unidades del kernel. La dirección final apunta a nt!KeAccumulateTicks, lo cual es habitual: el watchdog se dispara desde la contabilidad de tiempo del kernel, no desde la DPC culpable. Causas frecuentes: driver con DPC excesivamente larga, problema de firmware/BIOS que bloquea la CPU, o controlador de almacenamiento (storport/NVMe) bajo presión. Recomendaciones iniciales: actualizar BIOS, drivers de chipset y de almacenamiento; revisar utilidades de fabricante que interactúen con el firmware; ejecutar LatencyMon en estado normal de uso.
El culpable: una suite de seguridad SGX-aware que abusa de SMM
En el caso real que motiva este artículo, el responsable resultó ser un patrón más sutil que el clásico abuso de SMI por una utilidad de fabricante. La cadena fue ésta:
El driver kernel-mode del agente EDR ejecuta cada 5–8 segundos una secuencia que termina escribiendo en una MSR registrada por el firmware como gatillo de software SMI. La razón nominal es muestrear el estado de los enclaves cargados: número, identidad, signature hash, y la última información de la atestación.
El handler SMI correspondiente, alojado en SMRAM, hace dos cosas distintas. Primero, lee un puñado de MSRs relacionados con SGX (IA32_SGXLEPUBKEYHASH0..3, IA32_FEATURE_CONTROL, revisión de microcódigo, indicadores de SGX2). Esa parte es barata: decenas de microsegundos. Segundo, y aquí es donde el handler pierde la inocencia, consulta a Intel Management Engine vía la interfaz HECI/MEI para validar el estado de las claves de atestación. Esa consulta puede gastar entre 5 y 15 ms según lo que ME esté haciendo en su propio dominio, que el SO ni ve ni controla.
A la vez, cada SMI invocado mientras hay enclaves activos provoca un Asynchronous Enclave Exit en cada núcleo donde un enclave estuviera en ejecución. Recordemos lo establecido en la entrada del 15 de mayo: SMM no puede leer el EPC, pero la transición no es gratuita. Cada AEX implica salvar el estado del enclave en la SSA, sustituir los registros visibles por valores sintéticos, y, al volver, un ERESUME que cuesta del orden de 50–200 µs por núcleo afectado.
Multiplicado por la cadencia observada de 8–15 SMIs por segundo (los 116 / 10s que vimos en MSR 0x34), y por dos o tres enclaves activos durante la jornada, el sistema acumula ventanas SMM que en el peor caso, cuando ME está contendido por sus propias tareas de fondo, superan el umbral del DPC watchdog y disparan el 0x133.
Lo elegante de este patrón es doble. Por un lado, WER no puede ver nada de lo anterior: el handler vive en firmware, la consulta a ME ocurre fuera del espacio observable por el kernel, y el AEX se resuelve antes de que el SO siquiera registre que la SMI ha existido. El bucket dice nt!KeAccumulateTicks y se queda tan tranquilo. Por otro lado, el coste indirecto sobre el rendimiento de los enclaves SGX (la degradación silenciosa que no llega a BSOD pero ralentiza cualquier carga confidencial seria) es invisible para el equipo de seguridad que opera la suite: ellos miden el coste de su agente en espacio de usuario, donde la huella es un servicio que consume 20 MB de RAM y 0,3% de CPU. La factura real, pagada en latencia SMM y en throughput de enclave, queda fuera de su panel.
La resolución, una vez identificado el patrón, es proporcional:
Desactivar el módulo SGX Visibility del EDR en la consola del agente. El resto del EDR (detección de comportamiento, prevención de ejecución, telemetría kernel-mode) puede mantenerse intacto. La «visibilidad sobre enclaves» que se pierde con esto es, en la práctica, decorativa: el agente no podría inspeccionar el EPC ni aunque tuviese privilegio para hacerlo.
Si el equipo de seguridad necesita esa visibilidad por requisitos de compliance, migrar a herramientas basadas en DCAP (Data Center Attestation Primitives, parte del SGX SDK de Intel). DCAP expone el estado de los enclaves desde kernel-mode sin atravesar firmware: el coste, para el plano de la plataforma, es despreciable.
Para casos OEM con handlers HECI generosos, actualización de firmware a una versión donde la consulta a ME se difiera, se cachee o se agrupe.
Verificación posterior: el MSR 0x34 cae por debajo de 1 SMI/s en idle, LatencyMon vuelve a verde, el contador de AEX expuesto por el SGX SDK deja de mostrar correlación con la actividad del agente, y los 0x133 desaparecen del Visor de Eventos.
Referencias
Entrada relacionada en este blog: Forense de memoria en SGX ante sospecha de intromisión vía SMI (15 mayo 2026).
Entrada relacionada en este blog: Un molino llamado SMI: leer un BSOD con una IA local cuando el culpable no está donde Windows dice (CASO I) (18 mayo 2026).
A propósito de por qué el café del hotel pesa tanto como la nube de Washington
Hace unos días escribí en este mismo blog sobre Mythos, el modelo de Anthropic que volvía a desnudar la fragilidad estratégica europea: dependencia de la nube estadounidense, un interruptor de emergencia en manos ajenas y una Comisión que prefiere aplazar su propia regulación antes que arremeter contra los gigantes. Aquel post terminaba con una idea incómoda: la soberanía digital europea es, hoy por hoy, una ficción operativa.
Pues bien, lo de la nube y los modelos era sólo la mitad del problema. La otra mitad se esconde tras un gesto tan banal que precisamente por eso resulta demoledor: pagar un café.
El datáfono como infraestructura geopolítica
Acercas el móvil, suena el datáfono, sigues andando. El comercio cobra en euros, el impuesto se liquida en euros. Y, sin embargo, aquí está la trampa, una parte decisiva del trayecto no es europea.
Cerca de dos tercios de los pagos con tarjeta de la zona euro se procesan por esquemas no europeos. Trece países dependen por completo de ellos. La cifra, advierte el autor, no es técnica; es geopolítica.
Y entonces aparece, otra vez, la palabra. El sustantivo que El Quijote Digital lleva semanas persiguiendo: interruptor. Una infraestructura de pagos no es sólo una tubería; también es un interruptor que alguien puede condicionar, encarecer, retrasar o apagar. ¿Qué pasaría si nos sacan de VISA?
¿Os suena? Es exactamente la misma figura que el Future of Technology Institute utilizó hace unos meses para describir la dependencia europea de la nube estadounidense en defensa. Mismo verbo, mismo dueño, mismo continente atrapado.
Dos interruptores, un mismo problema
Conviene poner los dos casos uno al lado del otro, porque revelan un patrón que ya no admite la coartada del azar:
Caso Mythos / nube
Caso datáfono / pagos
Quién controla
Hiperescalares de EE.UU.
Visa y Mastercard
Qué controla
IA, defensa, infraestructura crítica
Pago cotidiano, comercios, liquidación
Punto de presión
Acceso al modelo, condiciones de uso
Acceso al esquema, tarifas, reglas
Reflejo europeo
«Hay que regularlo»
«Construyamos un euro digital»
Diagnóstico correcto
Construir capacidad europea
Construir red privada europea
Plazo realista
Sin fecha
2026–2027 (EPI / Wero)
Lo que aparece, leído así, no son dos crisis distintas: es la misma renuncia industrial repetida en dos capas tecnológicas distintas. Y en ambas la respuesta política instintiva ha sido idéntica: legislar lo que otros producen antes que producir algo propio.
Por qué el euro digital no es la respuesta
Frente a la dependencia de Visa y Mastercard, el reflejo de Bruselas ha sido apostar por el euro digital: una moneda pública, programable, emitida por el BCE. Suena bien, suena soberano, suena tecnológico. Pero cuando se diagnostica mal el problema, se receta mal la medicina.
El problema no es que falte una moneda. Es que falta una red privada de aceptación comercial capaz de competir con las americanas en lo que de verdad importa al comerciante y al usuario: aceptación, escala, experiencia de uso, antifraude, liquidación, marca.
«Europa no carece de moneda. Carece de raíles.»
El euro digital, además, llegaría tarde, el BCE habla de una posible emisión en 2029— y mal calibrado: con límites bajos servirá poco, con límites altos tensionará los depósitos bancarios, sin privacidad creíble nadie lo usará. En el mejor escenario es una herramienta complementaria. En el peor, una excusa elegante para no construir lo que sí hace falta.
Lo que sí podría funcionar: un Bizum europeo, sin metáforas
La alternativa real, tal como se explica en el artículo publicado con notable claridad por Omar Rachedi en «La soberanía pasa por el datáfono» (El País, 20 de mayo de 2026), es menos solemne, menos vistosa y, por eso mismo, mucho más prometedora. Existe ya un memorando entre Bizum, Wero, Bancomat, MB Way y Vipps MobilePay para crear una red interoperable capaz de funcionar de Lisboa a Helsinki sin que el usuario tenga que aprender nada nuevo. Pagos transfronterizos entre particulares en 2026, entre comercios en 2027.
¿Por qué esto sí puede salir adelante mientras otras ambiciones europeas se atascan? Porque, como bien apunta Rachedi, tiene una ventaja que Bruselas rara vez compra: el hábito. No exige convertir al ciudadano a una nueva fe monetaria ni convencerlo de un experimento institucional. Se apoya en bancos, aplicaciones y comportamientos que ya existen. El ciudadano español ya usa Bizum. El portugués ya usa MB Way. El alemán ya usa Wero. Sólo falta («sólo») que hablen entre sí.
Y aquí está el verdadero diagnóstico: Europa no fracasa por falta de ideas. Fracasa cuando veintisiete buenas ideas nacionales no se hablan entre sí. Lo cual es, dicho sea de paso, exactamente lo que le ocurre también en computación en la nube, en inteligencia artificial, en defensa, en semiconductores y en cualquier otro rincón del expediente tecnológico continental.
Euro digital como capa pública
Europa depende estructuralmente de redes de pago ajenas.
El dato del BCE (los esquemas internacionales de tarjetas representaban el 61% de los pagos con tarjeta en la zona euro en 2022), la inviabilidad de actuar país por país, y la oportunidad que abre el memorando firmado en febrero de 2026 entre Bizum, Wero, Bancomat, MB Way y Vipps MobilePay para acelerar pagos paneuropeos interoperables.
Cuestión a considerar: el papel del euro digital. ¿Es un placebo institucional que distrae del verdadero problema (faltan raíles, no moneda)?. O, el euro digital no es ni sustituto de Bizum ni solución milagrosa: es respaldo público en una economía donde el efectivo pierde peso. El argumento es sencillo y elegante: si el dinero público ha existido durante siglos en forma de billetes y monedas, ahora tiene que existir también digitalmente. No para desplazar lo privado, sino para impedir que el futuro de los pagos europeos dependa exclusivamente de redes privadas y externas.
Europa ya ha aprendido con la energía, los semiconductores o la defensa que las dependencias estratégicas:
«…suelen descubrirse tarde, cuando ya se han convertido en vulnerabilidades.»
A esa lista, hoy, hay que añadir la inteligencia artificial: véase Mythos. Y los pagos: véase el datáfono. Es exactamente el mismo patrón, repetido en distinto sector. Y siempre con el mismo retraso diagnóstico.
Entonces, ¿placebo o respaldo? Probablemente, los dos.
Por un lado no se pueden confundir prioridades: si el problema diario es que Visa y Mastercard procesan dos tercios de las transacciones europeas, lo urgente es construir red privada de aceptación, no acuñar moneda digital. Quien crea que el euro digital es la respuesta al problema de los pagos cotidianos en 2026, ha leído mal el problema. El euro digital, planificado para 2029 con un calibrado todavía incierto, no va a defendernos en el datáfono de mañana.
Por otro lado, se debe recordar que una vez resuelto el plano privado, el plano público sigue ahí. Si toda la infraestructura de pagos europea quedara únicamente en manos de un consorcio bancario privado, por muy europeo que sea, seguiríamos sin esa capa pública de seguridad que históricamente ha dado a los Estados el control último sobre su sistema monetario. Una capa, conviene recordar, que en formato físico llamamos billete del BCE y que nadie discute.
Dicho de otro modo, y a riesgo de simplificar: los raíles los pone el Bizum europeo; el aval último lo pone el euro digital. Lo urgente es lo primero. Lo estructural es lo segundo. Confundir el orden (que es lo que hoy hace Bruselas) equivale a fabricar una bóveda blindada para un edificio que aún no se ha levantado.
No olvidemos que…
«Pagar siempre ha sido una cuestión de poder.»
Lo fue cuando los Estados acuñaban moneda. Lo fue cuando se construyeron los grandes sistemas bancarios. Y lo es ahora, cuando los pagos se procesan mediante redes digitales globales. Europa, en su tránsito al euro, pareció olvidarlo. Ahora le toca recordarlo a base de sustos.
El interruptor también es ético
Permitidme cerrar atando el cabo con el post anterior. Cuando hablábamos de Mythos, señalábamos lo más alarmante: que Anthropic había declarado, con notable franqueza, que su ética se aplica únicamente a Estados Unidos. Pues bien, la lógica del datáfono es la misma, sólo que más discreta. Las reglas, las comisiones, los criterios de exclusión, las políticas antifraude, los términos y condiciones de Visa y Mastercard responden también a una jurisdicción que no es la nuestra. Y, llegado el caso, también pueden activarse, modificarse o suspenderse desde fuera.
La pregunta no es si eso ha ocurrido alguna vez, ha ocurrido, y no pocas. La pregunta es si Europa puede permitirse seguir construyendo su economía cotidiana sobre infraestructura que, cuando importa de verdad, no controla. La respuesta, como ya apunté a propósito de Mythos, debería sonrojarnos.
Coda quijotesca
Decíamos hace unos días que Bruselas, al revés que el hidalgo, confunde a los gigantes con molinos y prefiere no arremeter. El datáfono añade un matiz aún más amargo: hay días en que ni siquiera ve los molinos. Los toca con el móvil, oye un pitido, sigue andando. Y se dice a sí misma que aquello era sólo un café.
Pero no era un café. Era, os podéis imaginar, un interruptor.
Y el interruptor, como tantas veces en esta historia, no es nuestro.
Referencia
Rachedi, Omar. «La soberanía pasa por el datáfono». El País, 1ª edición, 20 de mayo de 2026, p. 12. Omar Rachedi es profesor de Economía de Esade.
Sobre CrashDetectorwithAI, los handlers en SMM que se exceden, y por qué decodificar un fault bucket no es lo mismo que entender un crash.
1. El abismo entre «se ha reiniciado» y saber por qué.
Cualquiera que haya pasado más de diez minutos administrando sistemas Windows conoce el ritual. Pantalla azul, código de error en hexadecimal, QR que nadie escanea, reinicio, y un Visor de Eventos que escupe un BugCheckCode y un FaultBucketId con la misma vocación divulgativa que una inscripción en arameo. El usuario medio (y muchos profesionales) hace entonces lo previsible: copia el código, lo lanza a Google, lee tres hilos de Reddit de 2019, actualiza un driver al azar y, si la cosa no vuelve a romperse en una semana, declara cerrado el incidente.
El problema, claro, no es el ritual. El problema es que ese ritual confunde correlación supersticiosa con diagnóstico. Y en Windows, donde el crash que ves rara vez es el crash que ocurrió, esa diferencia importa.Especialmente porque puede revelar intentos de persistencia, intrusiones, o áreas de exposición de tu infraestructura (como el caso que veremos en este post, que versa sobre una utilidad de fabricante haciendo outb 0xB2 periódico lo que provoca la activación de un handler SMI con busy-wait sin timeout sobre el Embedded Controller esto genera una ventana SMM > umbral DPC watchdog y salta el DPC_WATCHDOG_VIOLATION) ver Fig. 1.
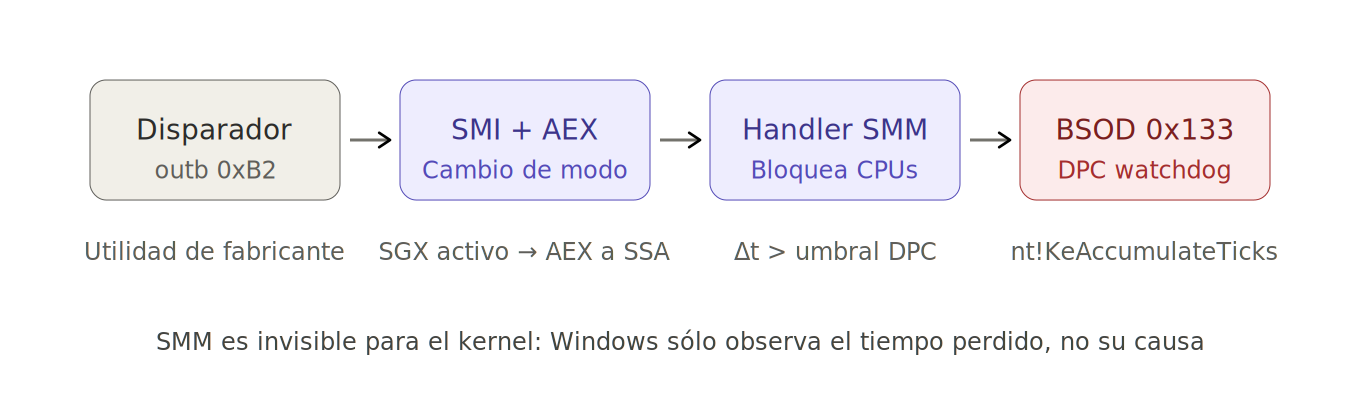
Fig. 1 — Anatomía del crash: el camino que va desde un outb 0xB2 inocente en espacio de usuario hasta la pantalla azul, pasando por dos modos de ejecución que Windows no puede instrumentar: una invocación SMI desde el modo de usuario (outb 0xB2) provoca, en sistemas con SGX activo, un Asynchronous Enclave Exit; el rendezvous SMM bloquea todos los núcleos mientras se ejecuta el handler; cuando el tiempo de espera supera el umbral, el kernel dispara DPC_WATCHDOG_VIOLATION.
El motivo de este post es probar una herramienta llamada CrashDetectorwithAI, de Claton Hendricks. Publicada bajo GPL-3.0 en GitHub (clatonhendricks/CrashDetectorwithAI), está construida con WPF sobre .NET 9 y ejecuta inferencia local de Phi-4 vía ONNX Runtime (con soporte alternativo a Ollama para quien prefiera Llama 3, Mistral, DeepSeek o Gemma). En cristiano: detecta eventos de crash, lee la información del fault bucket del Windows Error Reporting (WER) y se la entrega a un modelo pequeño que corre en tu máquina para devolverte una explicación legible y propuestas de solución, todo sin sacar un solo byte hacia la nube.
A primera vista parece un gadget de soporte técnico para cualquier usuario convencional. Y, en parte, lo es. Pero quien lleva tiempo en esto reconoce un segundo uso, mucho más interesante: es una herramienta didáctica para asomarse al subsistema de errores de Windows sin haberse leído antes los tres tomos de Russinovich. La gracia no está en que «te arregle el PC». La gracia está en que cada Blue Screen of Death (BSOD) se convierte en una oportunidad de aprender Windows por dentro.
Para ilustrarlo, os voy a desarrollar un caso realista (y, por motivos profesionales, que me ha ocurrido): un crash que Windows imputa formalmente a un driver inocente, cuando el verdadero culpable está varios anillos de privilegio más abajo, ejecutando en System Management Mode un handler que nunca debió ser tan generoso con el tiempo de espera (timeout).
Un System Management Interrupt (SMI) es la única interrupción que ningún sistema operativo puede enmascarar. La CPU abandona lo que esté haciendo, conmuta a System Management Mode, ejecuta un handler alojado en SMRAM y devuelve el control. Ese handler vive en firmware, no en el kernel de Windows.
En la mayoría de plataformas Intel, el SMI es un rendezvous síncrono entre todos los núcleos lógicos: cuando uno entra en SMM, los demás esperan. Si el handler tarda 200 ms, todo el sistema ha estado parado 200 ms. Windows no ha visto ese tiempo: para él, simplemente, no ocurrió.
WER, en cambio, sí ve las consecuencias: DPCs que no se entregan a tiempo, timers que no se sirven, watchdogs que se disparan. Y como WER no instrumenta SMM (no podría aunque quisiera), atribuye el accidente a la última víctima visible, normalmente un driver que llevaba encolada una DPC inocente.
Esta asimetría es la madre de un género entero de incidentes mal diagnosticados. El operador ve un DRIVER_VERIFIER_DETECTED_VIOLATION o un DPC_WATCHDOG_VIOLATION y, fiel al manual, jura y perjura contra el driver.
El driver, mientras tanto, mira de reojo a un handler de gestión térmica1 que se ha permitido un polling de 12 ms al Embedded Controller, multiplicado por los doce SMIs que dispara cada segundo una utilidad de fabricante que nadie pidió pero todos instalan.
3. La estación de trabajo que «falla aleatoriamente»
El escenario es banal. Windows 11, dos pantallas, treinta pestañas, un IDE, y la suite de monitorización térmica/RGB del fabricante de la placa base instalada de fábrica. Efectos:
BSOD intermitentes, una o dos veces por semana.
Bug check siempre el mismo: 0x133 (DPC_WATCHDOG_VIOLATION).
Sin patrón aparente. A veces compilando, a veces viendo Netflix, a veces con la máquina prácticamente ociosa.
El primer reflejo (el malo) es revisar drivers gráficos, de red y de almacenamiento. El segundo (también malo) es pasar el verifier.exe en modo paranoico, lo que dispara más BSODs sin acercar la respuesta. El tercero (el útil) es preguntarse qué dice exactamente WER.
Verifier.exe (Administrador del Verificador de controladores) es una herramienta nativa de Windows diseñada para probar y depurar controladores de dispositivos (drivers). Su función principal es estresar los controladores del sistema en tiempo real para detectar fallos, corrupción de memoria o incompatibilidades antes de que provoquen bloqueos graves.
¿Para qué se utiliza?
Diagnóstico de Pantallazos Azules (BSOD): Si tu sistema se bloquea frecuentemente, esta herramienta ayuda a identificar exactamente qué controlador está causando el error (y como vamos a ver, no siempre ese es el motivo).
Validación de controladores: Comprueba si los drivers están firmados digitalmente o si fueron creados para versiones anteriores de Windows.
Herramienta para desarrolladores: Ofrece opciones avanzadas para estresar la memoria I/O y registrar llamadas de sistema problemáticas.
Precauciones importantes
Dado que fuerza a los controladores a operar bajo condiciones extremas, puede causar pantallazos azules (BSOD) intencionales si detecta un fallo. Se recomienda utilizarlo únicamente en fases de depuración o cuando tu ordenador de uso diario esté experimentando fallos recurrentes y necesites encontrar al culpable.
Abrimos CrashDetectorwithAI tras el siguiente crash. La aplicación, sin que tengamos que tocar wer.dll ni rebuscar en C:\ProgramData\Microsoft\Windows\WER\ReportArchive\, presenta de forma estructurada algo equivalente a esto:
Crash event detected
─────────────────────────────────────────────
EventID: 1001 (BugCheck)
BugCheckCode: 0x00000133
Parameters: 0x0000000000000000
0x0000000000000501
0x0000000000000500
0xFFFFF80712345678
FaultBucketId: 0x133_0_nt!KeAccumulateTicks
ReportSignature: BlueScreen / 133 / nt / 10.0.26100.xxxx
WHEA records: none in last 5s
Minidump: C:\Windows\Minidump\051826-...dmp
Y, debajo, la respuesta del modelo local (Phi-4 vía ONNX) en streaming, que viene a decir, con palabras propias y prudentes, algo como (traducido y simplificado para cualquier lector):
Se trata de un DPC_WATCHDOG_VIOLATION. El parámetro 1 con valor 0 indica que se ha superado el umbral acumulado de DPC en un solo procesador. Los valores 0x501 y 0x500 son los *ticks* observado y permitido, expresados en unidades del kernel. La dirección final apunta a nt!KeAccumulateTicks, lo cual es habitual: el watchdog se dispara desde la contabilidad de tiempo del kernel, no desde la DPC culpable. Causas frecuentes: driver con DPC excesivamente larga, problema de firmware/BIOS que bloquea la CPU, o controlador de almacenamiento (storport/NVMe) bajo estrés. Recomendaciones iniciales: actualizar BIOS, drivers de chipset y de almacenamiento; revisar utilidades de fabricante que interactúen con el firmware; ejecutar LatencyMon en estado normal de uso.
Hagamos un alto aquí, porquq esta IA me está diciendo cosas raras, raras.
4. Qué hace bien la IA local, y dónde se cohíbe por diseño
La respuesta anterior es útil y razonablemente correcta. Y, lo que me parece más relevante, está calibrada: no afirma que un driver concreto sea el culpable, no inventa números, y menciona la posibilidad de un problema de firmware. Para un usuario que de otro modo habría reinstalado el driver de la NVIDIA por tercera vez, es un salto cualitativo.
Pero conviene mirar también lo que la IA no puede saber, y que cualquier ingeniero con experiencia sabe inferir:
El fault bucket es un agregador, no una causa. 133_0_nt!KeAccumulateTicks significa literalmente «aquí saltó el contador», no «aquí estaba el bug». Quien escribió el agrupador de WER lo hizo para que Microsoft pueda agrupar millones de telemetrías por similitud, no para que tú identifiques al responsable.
WER no instrumenta SMM. No hay forma, desde el espacio kernel, de que nt!KeAccumulateTicks te diga «he perdido 400 ms porque el procesador estaba en Ring −2 ejecutando código de firmware». El kernel ve el reloj saltar, no quién lo robó.
Phi-4 (o cualquier modelo de propósito general de pocos miles de millones de parámetros) no ha leído tu DSDT, tu SSDT, ni el datasheet del chipset de tu placa. Sabe en abstracto que SMIs largos pueden disparar 0x133. No sabe si los tuyos lo están haciendo.
DSDT y SSDT son tablas ACPI fundamentales en el firmware de tu placa base que comunican al sistema operativo cómo funcionan componentes como la CPU, los puertos USB y la energía.
Diferencias Clave
DSDT (Differentiated System Description Table): Es la tabla principal que describe la configuración base y todos los dispositivos principales del hardware de tu equipo. Solo existe una por sistema.
SSDT (Secondary System Description Table): Son tablas secundarias y modulares que describen componentes específicos (como la gestión de energía de la CPU o tarjetas gráficas). Un sistema puede tener múltiples SSDTs.
La buena noticia es que estos tres techos son metodológicos, no propios de la herramienta. La herramienta hace lo que sabe hacer, y lo hace bien: traducir, contextualizar y orientar. Lo que sigue es trabajo humano y, sobre todo, instrumentación. Para que veáis que todavía la IA no os va a sustituir :).
5. Bajar al cuarto de máquinas: medir SMI desde el SO
Si sospechamos que el handler SMI es el problema, hay que demostrarlo. Windows expone, indirectamente, la información suficiente.
5.1. Contador de SMI por núcleo (MSR 0x34)
En procesadores Intel, el MSR 0x34 (MSR_SMI_COUNT) es un contador monotónico de SMIs servidos por ese núcleo lógico desde el último reset. Con RWEverything, ChipSec o un driver de lectura de MSRs, se obtiene una lectura trivial:
chipsec_util msr 0x34
En una máquina sana en idle, ese contador debería incrementarse del orden de unas pocas unidades por minuto, o menos. Si en una máquina con la utilidad del fabricante activa observamos algo como:
…es decir, en torno a 12 SMIs por segundo en reposo, ya tenemos un primer indicador objetivo. No prueba la causa, pero sí que algo en la plataforma está disparando SMIs con una frecuencia que ningún diseño térmico razonable justifica.
5.2. Latencia de SMI con LatencyMon o WPA
LatencyMon (Resplendence) ofrece el indicador clínico más legible: highest measured interrupt to process latency. En el caso que nos ocupa, valores > 1500 µs en hard pagefault path y > 4000 µs puntuales son banderas rojas. El propio LatencyMon, en sistemas afectados, suele mostrar el mensaje canónico: «Your system appears to be having difficulty handling real-time audio and other tasks. […] One or more DPC routines that belong to a driver running in your system appear to be executing for too long […]». Mensaje engañoso, porque el driver que aparece en la columna acumulada de DPC suele ser inocente: en realidad ha sido desplazado en el tiempo por la ventana SMM, y el contador lo acusa a él.
Más rigurosa es la traza con Windows Performance Recorder y el perfil de CPU usage + Power, abierta en Windows Performance Analyzer. La columna SMI del System Activity aparece, en una máquina afectada, como un peine regular de picos coincidiendo con cada disparo del handler.
5.3. Cruzar con WHEA
Aunque WER lo silencia, el subsistema WHEA (Microsoft-Windows-WHEA-Logger) a veces deja rastro: PCIe Correctable Errors sin sentido aparente, thermal throttling notifications periódicas, o eventos BIOS error record (Event ID 47). Cuando aparecen sincronizados con los picos de SMI, la hipótesis se refuerza.
6. El culpable: un handler térmico, generoso, que gasta tiempo como si la máquina fuera suya, disparado por una utilidad de RGB
En el caso real que motiva este artículo, el responsable resultó ser una combinación sorprendente:
El servicio en segundo plano de la suite del fabricante cuya marca omito porque no quiero crear polémica (control de iluminación, perfiles térmicos, overclock asistido) escribe periódicamente en el puerto 0xB2 (APMC, Advanced Power Management Control), el método canónico para invocar un software SMI y solicitar al firmware una lectura de sensores.
El handler SMI correspondiente en el firmware UEFI realiza esa lectura secuencialmente sobre el Embedded Controller vía protocolo ACPI EC, esperando handshakes del EC con un busy-wait sin timeout agresivo.
Cada invocación gasta entre 150 y 400 µs en condiciones normales, pero ante una mínima contención del EC (por ejemplo, durante una transición de estado de la batería en portátiles, o coincidiendo con eventos de teclado en estaciones con KVMs USB) salta a 8–12 ms.
Multiplicado por una cadencia de 10–15 SMIs/s, el sistema acumula ventanas SMM que, en el peor caso, superan el umbral del DPC watchdog y disparan el 0x133.
Lo elegante de este patrón es que WER no puede ver nada de lo anterior. Lo único que ve es que nt!KeAccumulateTicks se sorprendió de cuánto tiempo había pasado. Y el informe agrupado, así lo dice.
La resolución, una vez identificado el patrón, es banal:
Actualización de BIOS a la versión donde el OEM corrige el busy-wait del handler de lectura de sensores (en este caso, una nota de release de tres líneas que sólo menciona «improved system stability under sustained sensor polling»).
Desinstalación o, como mínimo, desactivación del servicio en segundo plano de la suite del fabricante; la lectura de sensores que necesite el usuario puede obtenerse con HWiNFO en lectura pasiva sin disparar SMIs adicionales.
Verificación posterior: MSR 0x34 baja a <1 SMI/s en idle, LatencyMon vuelve a verde, y los 0x133 desaparecen del Visor de Eventos.
7. Volver a la herramienta: qué se aprende por el camino
Si has llegado hasta aquí siguiendo el post, te habrás dado cuenta de algo: CrashDetectorwithAI no diagnosticó el problema. No podía. Lo que hizo, y lo hizo bien, fue:
Sacar a la luz el FaultBucketId y el BugCheckCode con sus parámetros, sin que el usuario tuviera que rebuscar en WER\ReportArchive.
Traducirlos a una explicación calibrada y útil para empezar a pensar.
Sugerir, entre otras cosas, «revisar utilidades de fabricante que interactúen con el firmware», que es exactamente el camino correcto.
Recomendar LatencyMon, que es la herramienta canónica para confirmar la hipótesis.
En otras palabras: el modelo local me puso en la pista correcta y se calló a tiempo. No fingió saber lo que no podía saber. No inventó un nombre de driver. No me mandó a desinstalar la GPU. Esa modestia, en una industria de chatbots que afirman con la misma confianza una verdad y un disparate, es una virtud técnica seria.
Hay además un argumento de soberanía que no quiero dejar pasar. La herramienta corre íntegramente en local: el fault bucket, los parámetros del BugCheck y, eventualmente, el contenido del minidump nunca salen de tu máquina. Para cualquier organización con datos sensibles, esto no es una preferencia estética: es la diferencia entre una herramienta usable y una herramienta vetada por cumplimiento. Phi-4 en ONNX Int4 ocupa una fracción de gigabyte y se ejecuta en CPU; Ollama abre la puerta a modelos mayores si la máquina lo soporta. En ambos casos, ningún tercero ve tus crashes.
8. Lecciones más allá del caso
Conviene formular en limpio:
El crash que ves rara vez es el crash que ocurrió. WER agrupa por consecuencia; el FaultBucketId es un identificador estadístico, no un diagnóstico.
SMM es invisible para el SO. Cualquier explicación de un BSOD que ignore la existencia del Ring −2 está, por construcción, incompleta. En máquinas con utilidades de fabricante particularmente entusiastas con outb 0xB2, esa incompletitud se vuelve operativa.
La IA local es un buen primer escalón, no el último. Su valor no está en sustituir al ingeniero, sino en acortar la distancia entre el código hexadecimal y la primera hipótesis razonable. Quien sabe leer un MSR no la necesita; quien no lo sabe, con ella aprende antes.
Phi-4 corriendo en tu máquina con licencia GPL-3.0 no es un juguete. Es una demostración mundana, sin marketing, de para qué sirven realmente los modelos pequeños: convertir telemetría opaca en lenguaje natural sin entregar la telemetría a nadie.
La industria de la IA lleva tres años convenciéndonos de que su utilidad pasa por mandarlo todo a la nube. Herramientas como CrashDetectorwithAI recuerdan, con discreción, que también se puede al revés: traer el modelo a la máquina, dejar el dato quieto, y usar la inferencia para enseñar en lugar de opinar. Si alguna pedagogía de la administración de sistemas merece la pena en 2026, probablemente sea esta.
Y, claro, queda el viejo asunto de fondo: la BSOD seguirá llamándose pantalla azul, el 0x133 seguirá apuntando a nt!KeAccumulateTicks, y la próxima utilidad de RGB que alguien instale seguirá invocando outb 0xB2 con la inocencia del que cree que el firmware está para servirle. Don Quijote, recordemos, no se quejaba de que hubiera molinos. Se quejaba de que nadie quisiera mirarlos de cerca.
Microsoft Learn. Bug Check 0x133: DPC_WATCHDOG_VIOLATION.
Intel. Intel® 64 and IA-32 Architectures Software Developer’s Manual, Vol. 3C — System Management Mode.
Resplendence Software. LatencyMon: Real-time monitor for kernel latency.
Notas al pie
Espero que algún estudiante de Periféricos e Interfaces llegue a leer esto, pero he aquí la importancia de entender la gestión térmica (como vimos en clase) porque disparará al SMI. ↩︎
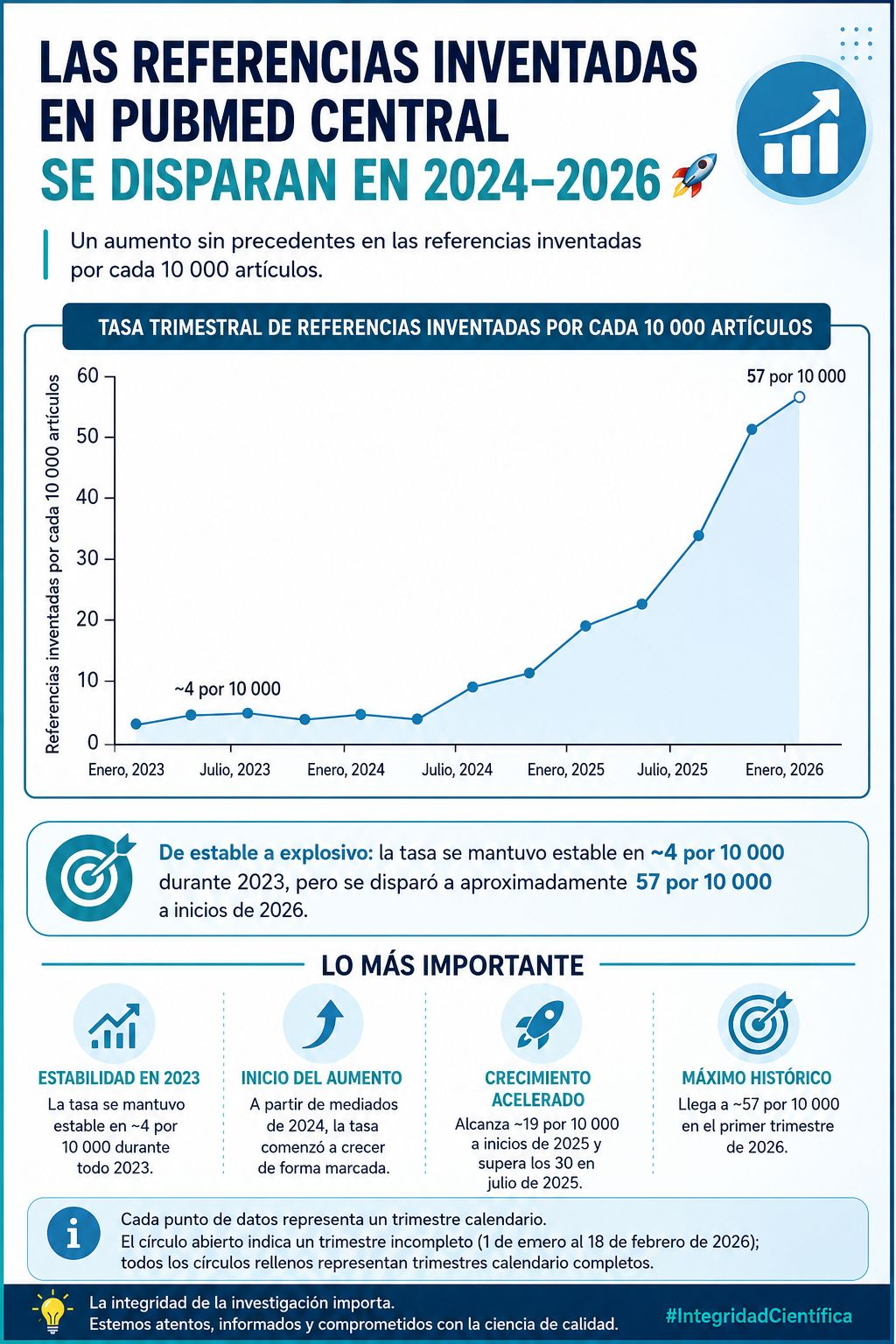
Hay una clase profesional que ha logrado algo extraordinario: convertir el conocimiento en moneda y, al mismo tiempo, vaciarlo de contenido. Se hacen llamar investigadores. Llevan corbata o americana de pana, ocupan despachos con ventana, dirigen tesis que no leen y firman artículos que no han escrito. Su patria es el cuartil. Su himno, el factor de impacto. Su dios, un acrónimo: JCR.
Conviene decirlo sin anestesia: el sistema Journal Citation Reports (y la liturgia universitaria que se ha construido a su alrededor) se ha convertido en uno de los mayores fraudes intelectuales de nuestro tiempo. No porque medir la ciencia sea malo, sino porque hemos sustituido la ciencia por la métrica. Y cuando la métrica se vuelve el objetivo, deja de medir nada. Lo formuló Goodhart hace décadas. Lo viven cada día miles de doctorandos que aprenden, antes que a pensar, a optimizar.
El arte de no aportar nada y firmarlo entre ocho
Asómese cualquiera a las bases de datos. Verá artículos firmados por diez, doce, quince autores en disciplinas donde el laboratorio cabe en un cajón. Verá catedráticos cuya producción anual rivaliza con la de un equipo de cien personas, milagro explicable solo si admitimos que han descubierto el secreto de la bilocación o, más prosaicamente, que han descubierto el intercambio cruzado de autorías. Yo te pongo en el mío, tú me pones en el tuyo, y al final del sexenio nos vamos los dos a cenar. Ciencia colaborativa, lo llaman. Mafia, lo llamaríamos en cualquier otro sector.
La autoría honorífica (ese eufemismo cobarde para nombrar el robo intelectual) se ha normalizado hasta tal punto que ya nadie se sonroja. El director del departamento firma sin haber leído. El catedrático firma porque «ha dado ideas» hace tres años en un café. El amigo firma para que devuelva el favor el trimestre siguiente. Mientras tanto, el becario que escribió cada coma del manuscrito aparece en cuarta posición, agradecido de que le hayan dejado entrar en la fiesta de su propio trabajo.
La picaresca del cuartil
Los virtuosos del JCR han desarrollado un arsenal de técnicas que avergonzaría a un trilero de la Gran Vía:
El salchichón científico: dividir un estudio que cabría en un artículo serio en seis publicaciones famélicas, cada una con un dato y media conclusión, para multiplicar la cuenta.
Los cárteles de citación: grupos que se citan recíprocamente con la fidelidad de una secta, inflando artificialmente los índices h y manteniendo a flote revistas mediocres dirigidas por sus propios miembros.
El p-hacking y el HARKing: torturar los datos hasta que confiesen, y luego escribir la hipótesis después de conocer el resultado, fingiendo que se predijo lo que ya se sabía.
La revista amiga: ese Q1 sospechosamente endogámico donde publican siempre los mismos, revisados por los mismos, citados por los mismos.
El paper de pago disfrazado: el «open access» que de abierto solo tiene el bolsillo, donde por dos mil euros publican lo que sea con tal de que el cheque no rebote.
Y luego están, claro, los casos abiertamente fraudulentos: figuras manipuladas con Photoshop, datos inventados, ensayos clínicos que nunca existieron. Los retractan a veces. Pocas veces. Y cuando ocurre, el firmante sigue en su cátedra, sigue presidiendo tribunales, sigue dirigiendo tesis. Porque en la universidad española (y en muchas otras) ser pillado mintiendo cuesta menos que ser pillado siendo honesto y poco productivo.
¿Para quién trabajamos?
Lo más obsceno del sistema no es siquiera la trampa individual. Es que toda esta maquinaria (pagada con dinero público, sostenida por el trabajo gratuito de miles de revisores, alimentada por la ansiedad de doctorandos sin contrato) engorda los beneficios de cuatro multinacionales editoriales que cobran márgenes superiores a los de Apple. Elsevier, Springer, Wiley, Taylor & Francis. Compramos a precio de oro lo que les hemos regalado, y encima les damos las gracias por permitirnos hacerlo.
Mientras tanto, la sociedad que financia todo esto recibe ¿qué? Artículos en inglés, encerrados detrás de muros de pago, escritos en una jerga deliberadamente impenetrable, sobre cuestiones que ni el propio autor cree relevantes pero que daban para un Q1. Estudios que nadie replicará (porque replicar no puntúa). Conclusiones que no llegarán al aula, ni al hospital, ni al taller, ni al campo. Conocimiento producido en circuito cerrado para consumo de la propia tribu.
La crisis de replicabilidad es la confesión silenciosa de todo esto: en psicología, en biomedicina, en economía, la mitad o más de los resultados «consolidados» se evaporan cuando alguien se molesta en comprobarlos. Pero qué importa: los autores ya tienen su plaza, ya tienen su sexenio, ya tienen su ANECA. La verdad puede esperar. El cuartil no.
La complicidad institucional
Habría que ser ingenuo para creer que esto se sostiene solo por la codicia de unos pocos. Lo sostienen las agencias evaluadoras, que llevan décadas externalizando su criterio a un índice privado, opaco y comercial diseñado en los años sesenta para librarías. Lo sostienen los rectorados, que presumen de rankings construidos sobre las mismas cifras. Lo sostienen los gobiernos, encantados de poder gestionar la ciencia con una hoja de cálculo. Y lo sostiene también una parte del profesorado, que en su día tragó con las reglas para sobrevivir y ahora las exige a la generación siguiente con el rencor del converso.
Resulta sintomático que España, país que tantas veces se queja de su atraso científico, haya construido un sistema de promoción académica donde es perfectamente posible llegar a catedrático sin haber tenido jamás una idea original, simplemente acumulando JCRs como quien acumula sellos.
Abolir el JCR no es suficiente, pero es por donde empezar
No se trata de renunciar a evaluar. Se trata de evaluar lo que importa. Evaluar la calidad antes que la cantidad. Evaluar el contenido antes que el continente. Evaluar la honestidad, la replicabilidad, la utilidad social, la formación de discípulos, la divulgación, la integridad. Hay alternativas, y existen desde hace años: la Declaración DORA, el Manifiesto de Leiden, la ciencia abierta, la revisión por pares transparente, los repositorios públicos, las métricas responsables. Lo que falta no es técnica. Falta voluntad. Y falta vergüenza.
Mientras tanto, conviene nombrar las cosas por su nombre. Quien firma lo que no ha escrito, miente. Quien intercambia autorías, defrauda. Quien fabrica datos, prevarica con dinero público. Quien preside tribunales sabiendo que el sistema premia a los tramposos, es cómplice. Y quien defiende este sistema porque le ha ido bien dentro de él, no defiende la ciencia: defiende su currículo.
La universidad puede ser muchas cosas. Pero si renuncia a la verdad —si la convierte en un trámite, en una métrica, en un negocio— deja de ser universidad y se convierte en una agencia de colocación con biblioteca. A estas alturas, ya no estamos seguros de cuál es cuál.
El día que un comité de evaluación pregunte «¿qué ha descubierto usted?» en lugar de «¿cuántos Q1 tiene?», empezaremos a tener algo parecido a una comunidad científica. Hasta entonces, seguiremos teniendo lo que tenemos: una burocracia con bata blanca.